k-means clustering |
|
The k-means clustering basically groups pixels according to their color similarity. The number of groups corresponds to the number of the defined clusters. The grouping is done iteratively by minimizing the sum of squares of distances between the pixel intensity and the corresponding cluster centroid. For grayscale images, the process groups pixels according to the gray level similarity. |
![]() Note: For aborting
the process, click on the progress bar.
Note: For aborting
the process, click on the progress bar.
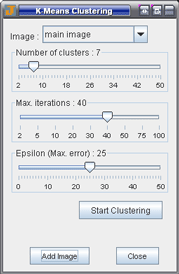
Image: Select an image.
Number of clusters: Set the final number of clusters.
Max. iterations: Define the maximum number of iterations to stop the clustering.
Epsilon (Max. error): Define the tolerable error. When the difference between the pixels less the cluster centroids in the last and the previous iteration is less than the error, the clustering is stopped.
![]() See
also:
See
also: